
Any distribution organization that sells a solution with many options, components or parts has a significant challenge when it comes to providing documentation for their customers, as well as internal teams. Complex configurable products and solutions can have large numbers of possible combinations and variations that can lead to a “combinatorial explosion” where documentation costs skyrocket and become economically unsustainable.
Many traditional content, document or knowledge management and product information systems are not built to support documentation for products that have large numbers of variations in configuration. This leads to higher support costs and workflow and logistical problems with updating documentation throughout the product lifecycle.
Use Cases
- In machinery manufacturing, multiple types and models of industrial machines are available to meet the needs and specifications of each customer. Each customer receives a custom configuration of the machine, and maintenance engineers must have quick access to the documentation on the machine requiring maintenance.
- In aerospace, each aircraft model has multiple modifications, so no two aircraft have the same configuration. When an airline receives a custom configured aircraft, all modifications that differ from the base model have to be properly documented.
- Many companies grow through acquisition, and supporting multiple products and product lines with a large and growing, multi-lingual customer base can be a challenge.
Enter Component Content
The answer is to break content up into smaller, reusable pieces that can be reassembled based on configuration choices. DITA (Darwin Information Typing Architecture) is the standard used to design component content. This approach ensures that the correct content is associated with each configured product variation. It allows customer service reps to locate specific knowledge associated with product combinations and variations, and can also automate conversational access to question-answering systems.
Component content can be used in a variety of ways, either feeding downstream systems (website, customer support, configure price quote, etc.). It can also be fed by upstream systems such as product information and product content management systems, as well as customer support and self-service. See Figure 1.
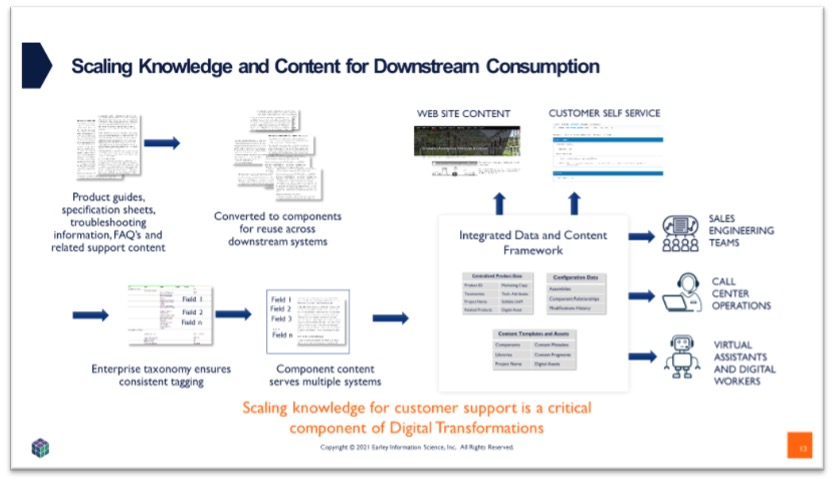
Data flows can become quite complex for large distributors and manufacturers when data governance, reporting requirements and supplier/partner/distributor feeds are added in. See figure 2.
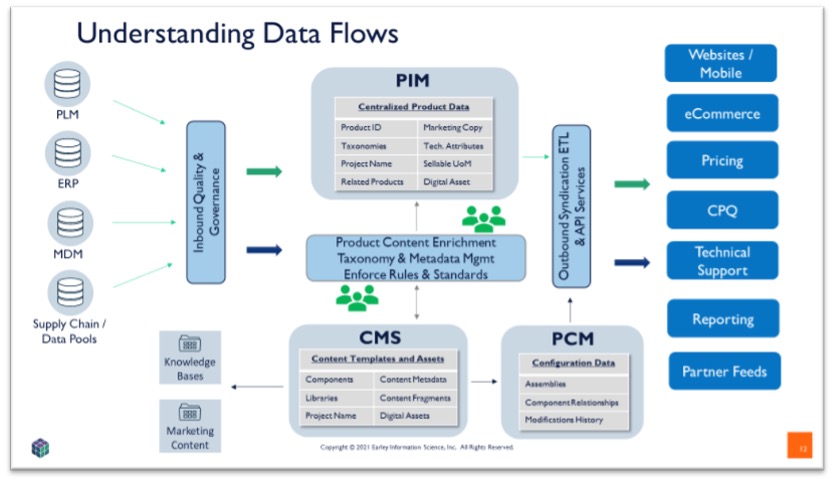
Technology + Information Architecture to Support Component Content
Many elements need to be aligned for component content to correctly support complex configurations. This begins with the correct taxonomies – a hierarchical, parent child whole/part collection of terms representing products and concepts related to the support and service of those products. Multiple taxonomies represent various elements of the knowledge and product domain: Product categories, product families, product type, solutions, troubleshooting processes, problem topics and more.
It is not unusual to have 10 or more hierarchies or facets. These dimensions of knowledge concepts and their relationships (troubleshooting processes for each product type, for example, problem topic and solution pairs, etc.) become the ontology. The ontology is the knowledge scaffolding for the organization. Content models, metadata structures, content profiles, components and standards are designed using the ontology. Until this structure is in place, component content is not feasible.
Conversational Access
With componentized content and a strong information architecture in place, some interesting future possibilities open up, such as serving up content through a chat question answering/FAQ bot. In the future, a maintenance engineer will be able to walk up to a machine and ask it what maintenance procedures it needs or, with the right integrated diagnostics what parts need to be replaced.
In conclusion, you can create customized documentation for complex products economically by componentizing your documentation and integrating it with well-architected information systems.
Seth Earley is the founder & CEO of Earley Information Science. The company provides consulting services helping clients to achieve higher levels of operating performance by making information more findable, usable and valuable through integrated enterprise architectures supporting analytics, e-commerce and customer experience applications. He is also the author of “The AI-Powered Enterprise” from LifeTree Media.
Related Posts
-

Many distributors are under the assumption that if they load a bunch of content onto…
-
Many distributors are under the assumption that if they load a bunch of content onto…
-

Amazon’s success is not an accident. It is the result of imaginative planning, technological enablement…


